Finite Mixtures of Beta Regression for Rates and Proportions
Description
Fit finite mixtures of beta regression models for rates and proportions via maximum likelihood with the EM algorithm using a parametrization with mean (depending through a link function on the covariates) and precision parameter (called phi).
symbolic description of the model (of type y ~ x or y ~ x | z; for details see betareg).
data, subset, na.action
arguments controlling formula processing via model.frame.
weights
optional numeric vector of integer case weights.
offset
optional numeric vector with an a priori known component to be included in the linear predictor for the mean.
k
a vector of integers indicating the number of components of the finite mixture; passed in turn to the k argument of stepFlexmix.
link
character specification of the link function in the mean model (mu). Currently, “logit”, “probit”, “cloglog”, “cauchit”, “log”, “loglog” are supported. Alternatively, an object of class “link-glm” can be supplied.
link.phi
character specification of the link function in the precision model (phi). Currently, “identity”, “log”, “sqrt” are supported. The default is “log” unless formula is of type y ~ x where the default is “identity” (for backward compatibility). Alternatively, an object of class “link-glm” can be supplied.
control
a list of control arguments specified via betareg.control.
cluster
Either a matrix with k columns of initial cluster membership probabilities for each observation; or a factor or integer vector with the initial cluster assignments of observations at the start of the EM algorithm. Default is random assignment into k clusters.
FLXconcomitant
concomitant variable model; object of class FLXP. Default is the object returned by calling FLXPconstant. The argument FLXconcomitant can be omitted if formula is a three-part formula of type y ~ x | z | w, where w specificies the concomitant variables.
FLXcontrol
object of class “FLXcontrol” or a named list; controls the EM algorithm and passed in turn to the control argument of flexmix.
verbose
a logical; if TRUE progress information is shown for different starts of the EM algorithm.
nstart
for each value of k run stepFlexmixnstart times and keep only the solution with maximum likelihood.
which
number of model to get if k is a vector of integers longer than one. If character, interpreted as number of components or name of an information criterion.
ID
grouping variable indicating if observations are from the same individual, i.e. the component membership is restricted to be the same for these observations.
fixed
symbolic description of the model for the parameters fixed over components (of type ~ x | z).
specifies if the component follows a uniform distribution or a beta regression model.
coef
a vector with the coefficients to determine the midpoint of the uniform distribution or names list with the coefficients for the mean and precision of the beta regression model.
delta
numeric; half-length of the interval of the uniform distribution.
Details
The arguments and the model specification are similar to betareg. Internally stepFlexmix is called with suitable arguments to fit the finite mixture model with the EM algorithm. See Grün et al. (2012) for more details.
extra_components is a list where each element corresponds to a component where the parameters are fixed a-priori.
Value
An object of class “flexmix” containing the best model with respect to the log likelihood or the one selected according to which if k is a vector of integers longer than 1.
Author(s)
Bettina Grün and Achim Zeileis
References
Cribari-Neto F, Zeileis A (2010). Beta Regression in R. Journal of Statistical Software, 34(2), 1–24. doi:10.18637/jss.v034.i02
Grün B, Kosmidis I, Zeileis A (2012). Extended Beta Regression in R: Shaken, Stirred, Mixed, and Partitioned. Journal of Statistical Software, 48(11), 1–25. doi:10.18637/jss.v048.i11
Grün B, Leisch F (2008). FlexMix Version 2: Finite Mixtures with Concomitant Variables and Varying and Constant Parameters. Journal of Statistical Software, 28(4), 1–35. doi:10.18637/jss.v028.i04
Leisch F (2004). FlexMix: A General Framework for Finite Mixture Models and Latent Class Regression in R. Journal of Statistical Software, 11(8), 1–18. doi:10.18637/jss.v011.i08
See Also
betareg, flexmix, stepFlexmix
Examples
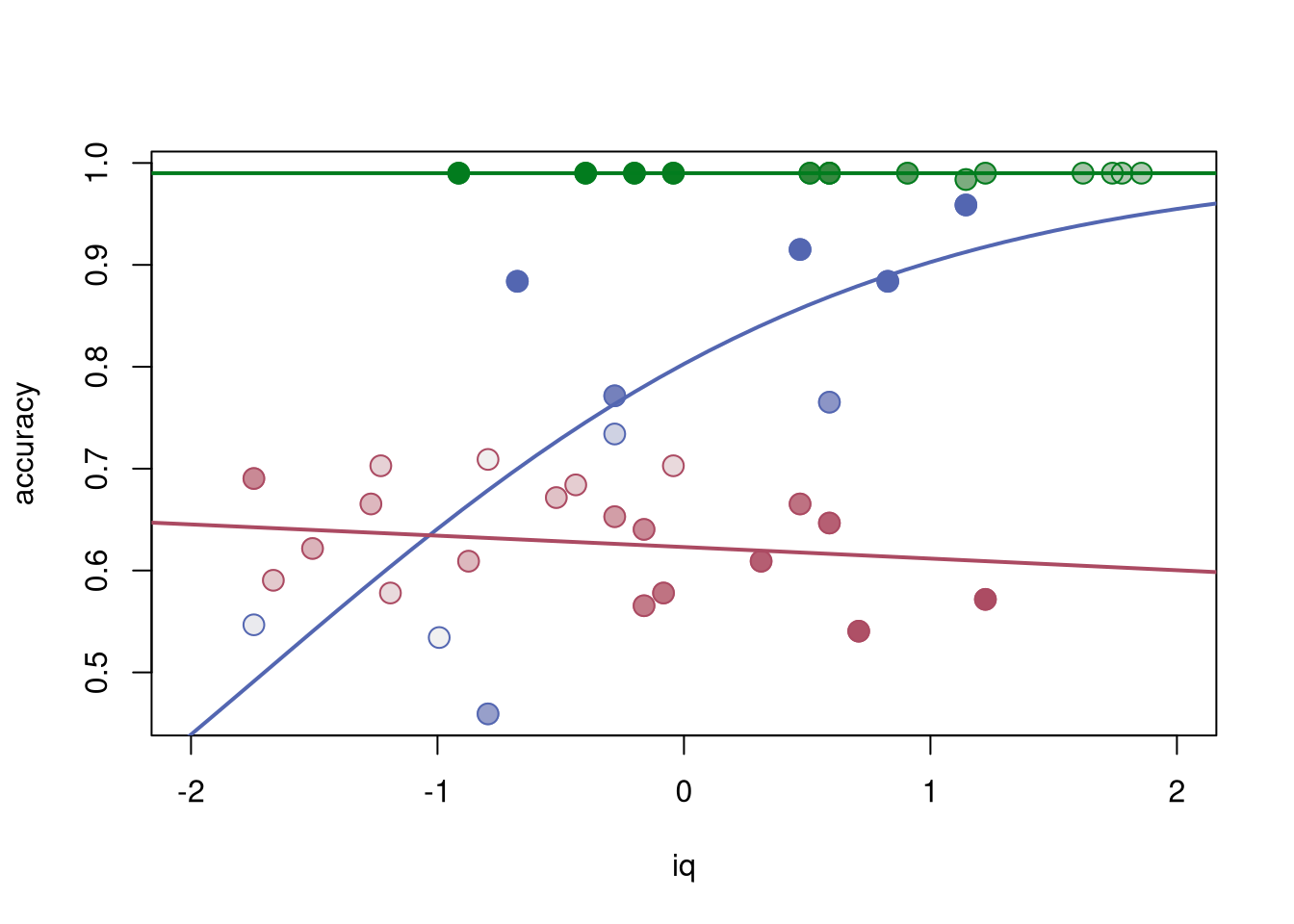
library("betareg")options(digits =4)## data with two groups of dyslexic and non-dyslexic childrendata("ReadingSkills", package ="betareg")suppressWarnings(RNGversion("3.5.0"))set.seed(4040)## try to capture accuracy ~ iq relationship (without using dyslexia## information) using two beta regression components and one additional## extra component for a perfect reading scorers_mix<-betamix(accuracy~iq, data =ReadingSkills, k =3, nstart =10, extra_components =extraComponent(type ="uniform", coef =0.99, delta =0.01))## visualize result## intensities based on posterior probabilitiesprob<-2*(posterior(rs_mix)[cbind(1:nrow(ReadingSkills),clusters(rs_mix))]-0.5)## associated HCL colorscol0<-hcl(c(260, 0, 130), 65, 45, fixup =FALSE)col1<-col0[clusters(rs_mix)]col2<-hcl(c(260, 0, 130)[clusters(rs_mix)], 65*abs(prob)^1.5,95-50*abs(prob)^1.5, fixup =FALSE)## scatter plotplot(accuracy~iq, data =ReadingSkills, col =col2, pch =19, cex =1.5, xlim =c(-2, 2))points(accuracy~iq, data =ReadingSkills, cex =1.5, pch =1, col =col1)## fitted linesiq<--30:30/10cf<-rbind(coef(rs_mix, model ="mean", component =1:2),c(qlogis(0.99), 0))for(iin1:3)lines(iq, plogis(cf[i, 1]+cf[i, 2]*iq), lwd =2, col =col0[i])
## refit the model including a concomitant variable model using the## dyslexia information with some noise to avoid complete separation## between concomitant variable and component membershipsset.seed(4040)w<-rnorm(nrow(ReadingSkills), c(-1, 1)[as.integer(ReadingSkills$dyslexia)])## The argument FLXconcomitant can be omitted when specifying## the model via a three part formula given by## accuracy ~ iq | 1 | w## The posteriors from the previously fitted model are used## for initialization.library("flexmix")rs_mix2<-betamix(accuracy~iq, data =ReadingSkills, extra_components =extraComponent(type ="uniform", coef =0.99, delta =0.01), cluster =posterior(rs_mix), FLXconcomitant =FLXPmultinom(~w))coef(rs_mix2, which ="concomitant")