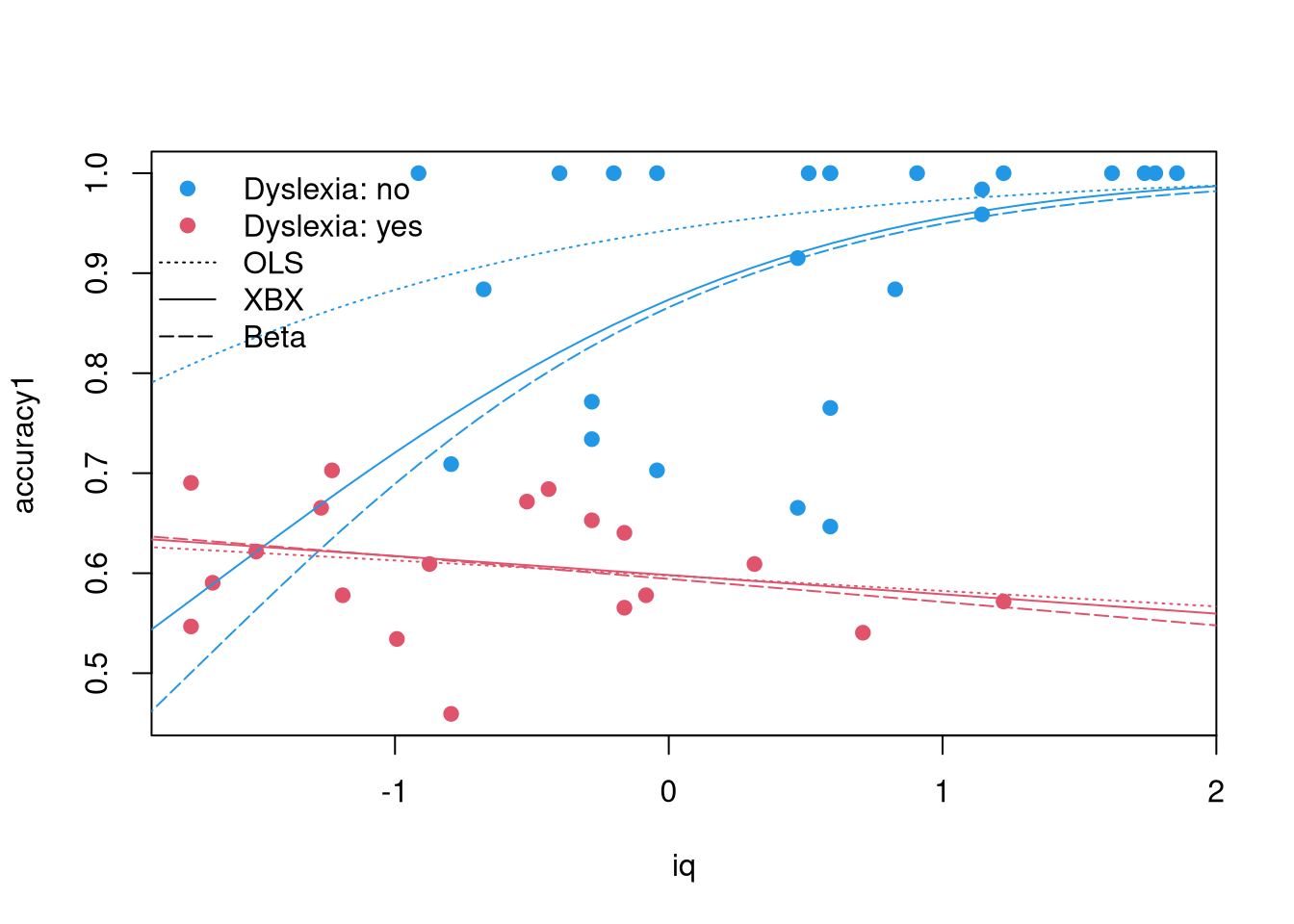
Data for assessing the contribution of non-verbal IQ to children’s reading skills in dyslexic and non-dyslexic children.
Usage
data("ReadingSkills", package = "betareg")
Format
A data frame containing 44 observations on 3 variables.
accuracy
numeric. Reading score with maximum restricted to be 0.99 rather than 1 (see below).
dyslexia
factor. Is the child dyslexic? (A sum contrast rather than treatment contrast is employed.)
iq
numeric. Non-verbal intelligence quotient transformed to z-scores.
accuracy1
numeric. Unrestricted reading score with a maximum of 1 (see below).
Details
The data were collected by Pammer and Kevan (2004) and employed by Smithson and Verkuilen (2006). The original reading accuracy score was transformed by Smithson and Verkuilen (2006) so that accuracy is in the open unit interval (0, 1) and beta regression can be employed. First, the original accuracy was scaled using the minimal and maximal score (a and b, respectively) that can be obtained in the test: accuracy1 = (original_accuracy - a) / (b - a) (a and b are not provided). Subsequently, accuracy was obtained from accuracy1 by replacing all observations with a value of 1 with 0.99.
Kosmidis and Zeileis (2025) propose to investigate the original unrestricted accuracy1 variable using their extended-support beta mixture regression.
Source
Example 3 from Smithson and Verkuilen (2006) supplements.
References
Cribari-Neto F, Zeileis A (2010). Beta Regression in R. Journal of Statistical Software, 34(2), 1–24. doi:10.18637/jss.v034.i02
Grün B, Kosmidis I, Zeileis A (2012). Extended Beta Regression in R: Shaken, Stirred, Mixed, and Partitioned. Journal of Statistical Software, 48(11), 1–25. doi:10.18637/jss.v048.i11
Kosmidis I, Zeileis A (2025). Extended-Support Beta Regression for [0, 1] Responses. Journal of the Royal Statistical Society C, forthcoming. doi:10.1093/jrsssc/qlaf039
Pammer K, Kevan A (2004). The Contribution of Visual Sensitivity, Phonological Processing and Non-Verbal IQ to Children’s Reading. Unpublished manuscript, The Australian National University, Canberra.
Smithson M, Verkuilen J (2006). A Better Lemon Squeezer? Maximum-Likelihood Regression with Beta-Distributed Dependent Variables. Psychological Methods, 11(7), 54–71.
See Also
betareg, MockJurors, StressAnxiety
Examples
library("betareg")options(digits =4)data("ReadingSkills", package ="betareg")## Smithson & Verkuilen (2006, Table 5)## OLS regression## (Note: typo in iq coefficient: 0.3954 instead of 0.3594)rs_ols<-lm(qlogis(accuracy)~dyslexia*iq, data =ReadingSkills)summary(rs_ols)
Call:
lm(formula = qlogis(accuracy) ~ dyslexia * iq, data = ReadingSkills)
Residuals:
Min 1Q Median 3Q Max
-2.6640 -0.3797 0.0369 0.4089 2.5035
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.601 0.226 7.09 1.4e-08 ***
dyslexia -1.206 0.226 -5.34 4.0e-06 ***
iq 0.359 0.225 1.59 0.119
dyslexia:iq -0.423 0.225 -1.88 0.068 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.2 on 40 degrees of freedom
Multiple R-squared: 0.615, Adjusted R-squared: 0.586
F-statistic: 21.3 on 3 and 40 DF, p-value: 2.08e-08
## Beta regression (with numerical rather than analytic standard errors)## (Note: Smithson & Verkuilen erroneously compute one-sided p-values)rs_beta<-betareg(accuracy~dyslexia*iq|dyslexia+iq, data =ReadingSkills, hessian =TRUE)summary(rs_beta)
Call:
betareg(formula = accuracy ~ dyslexia * iq | dyslexia + iq, data = ReadingSkills,
hessian = TRUE)
Quantile residuals:
Min 1Q Median 3Q Max
-2.362 -0.587 0.303 0.942 1.587
Coefficients (mean model with logit link):
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.123 0.151 7.44 9.8e-14 ***
dyslexia -0.742 0.151 -4.90 9.7e-07 ***
iq 0.486 0.167 2.91 0.00360 **
dyslexia:iq -0.581 0.173 -3.37 0.00076 ***
Phi coefficients (precision model with log link):
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.304 0.227 14.59 < 2e-16 ***
dyslexia 1.747 0.294 5.94 2.8e-09 ***
iq 1.229 0.460 2.67 0.0075 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Type of estimator: ML (maximum likelihood)
Log-likelihood: 65.9 on 7 Df
Pseudo R-squared: 0.576
Number of iterations in BFGS optimization: 25